

One of the most talented and profound colleagues I’ve had in my life has not been a person, but an algorithm: the Markov Chain. Our unlikely partnership spans three decades and is a New Year’s tale pouring out of a magician’s hacker hat, into a cosmic plasma, and through a mortgage closing optimizer.
Father’s Computer Magazine Treasure Trove
As a kid in the late 1980s I experienced the golden age of the print computer magazine. My dad subscribed to (seemingly) all of them, but my favorites were BYTE Magazine and PC/Computing, both now extinct publications. Since there was no internet, manually typing in and modifying printed computer programs was the way to try out other people’s code, and a favorite pastime of mine for a rainy Sunday afternoon.
It was nerdy fun: BYTE provided my first encounter with Chaos Theory, a branch of physics which predicts things like the probability that Mercury will be ejected from the solar system by millions of years of Jupiter slightly but persistently tugging on it:
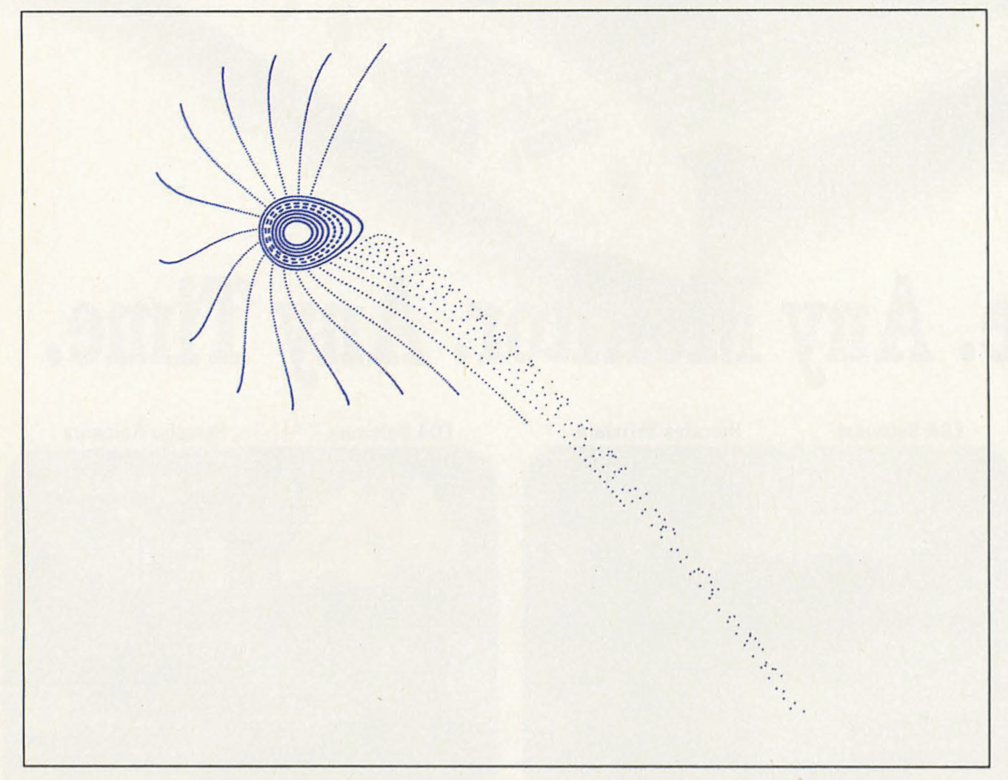
I was able to recreate complex orbital trajectories such as the above by typing in the program into my state-of-the-art 80486 PC. But, being a kid without a physics degree, it was simply mindless copypasta to me.
That changed, however, with a 1991 article by Penn Jillette, the more vocal half of the Penn & Teller miming magician duo that used to perform regularly in Vegas. Even then best known as a humorous illusionist, Jillette had a second career as a computer journalist for PC/Magazine. He always had something witty to say in his regular column, and one week the following title caught my eye:
I Spent an Interesting Evening Recently with a Grain of Salt
It turns out that a decade before the public-facing internet gained traction in the mid-’90s, universities were already busy spinning up its backbones. One such backbone was Usenet, a lawless Reddit-like discussion forum where life advice, political commentary, pirated software and media, bots, trolls, and all the other current features of internet forum banter were already taking shape. Jillette’s article described a poetic Usenet mad genius that turned out to be one of the first bots to grace online discussion forums.
The aptly named Mark V. Shaney bot operated by reading online discussion and passing it through an algorithm known as the Markov Chain, named after early 20th century Russian mathematician Andrey Markov. Jillette described how, by detecting which words patterns were most likely to follow each word, the bot could construct a dictionary which encapsulated the style of a discussion forum. For example, picking a phrase length of three words, the Mark V. Shaney bot would parse a familiar tonguetwister’s word combinations as follows:

Using the above frequencies, but applied to a much larger corpus, the Markov Chain algorithm would then generate text by randomly picking words according to the frequencies in which they appear, generating poetic phrases no person had produced before, such as the quip about the grain of salt, in the style of that which it had ingested.
This was an algorithm my kid self needed to program from scratch, since Jillette provided no code. My language of choice back then was BASIC, a popular beginners’ language. Nowadays, there are many online versions you can try, including one that will improvise on Alice in Wonderland, producing even more Carrollian utterances such as:
The croquet balls were live hedgehogs; and if I was, I shouldn’t want yours—I don’t take this child away with Alice.
Hotter than the Sun, Thinner than the Wind
Over the next 15 years, I forgot about the silliness of the Mark V. Shaney bot and its nonsense phrases. I was preoccupied with more serious things – or so I thought. In 2004, sitting on a perch in the ultra-thin air at 14,000 feet on Mauna Kea, Hawaii, vast structures preoccupied me. Giant regions of space so gargantuan that light itself took a million years to cross them.

The objects were the marvelous galaxy clusters, the largest structures in the universe, representing a level of hierarchy beyond the popular imagination. Much like how planets orbit stars, and stars orbit each other in a galaxy, galaxies orbit each other in a cluster. But none of these objects moves through truly empty space: planets move through the solar wind, stars move through the cold interstellar medium, and galaxies move through the hot intracluster medium (ICM).
The ICM is hot. Unimaginably hot: at 100,000,000 degrees celsius, it’s hotter than even the core of the sun. Yet paradoxically it is also unbelievably thin: emptier than the best vacuum we can make on earth, or even solar wind itself.
Building models of the ICM was incredibly important for many reasons, including the fact that it could help us understand mysterious dark forces and particles that fill our cosmos. But the models had many parameters that need to be tweaked in order to arrive at the ground truth measurement. It would have taken centuries to search all the possible parameters for the optimal combination.
Luckily, a technique was coming of age during that time that built on Andrey Markov’s idea and added an even more random component to it: the casino. The Markov Chain Monte Carlo (MCMC) technique adapted the Mark V. Shaney bot to problems involving numbers instead of words. By simply trying random combinations of numbers, but with proper statistical selection, the algorithm could arrive at the optimal solution much faster than brute force methods.
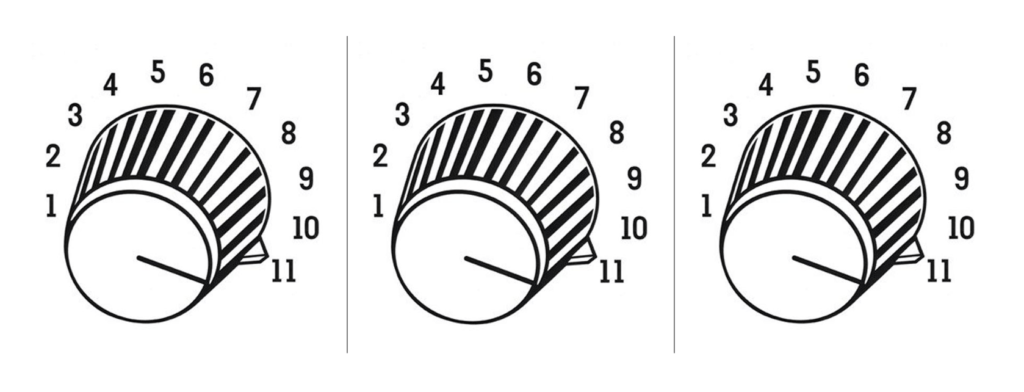
How did MCMC overcome the obstacles of brute force processes? Via statistics. Every time we try two different sets of knob combinations, we get a read on how good the model is (think of it as adjusting the equalizer on a stereo system… you play with the dials, and your ears tell you as you get closer to the sweet spot).
The better the model fits the data, the more optimal its performance. MCMC shows that by judicious “hopping” around different sets of knob settings, we can get very close to the correct answer very fast, much as the human ear does.
The chart below shows one potential way MCMC might optimize the three-knob equalizer for the sweetest sound:
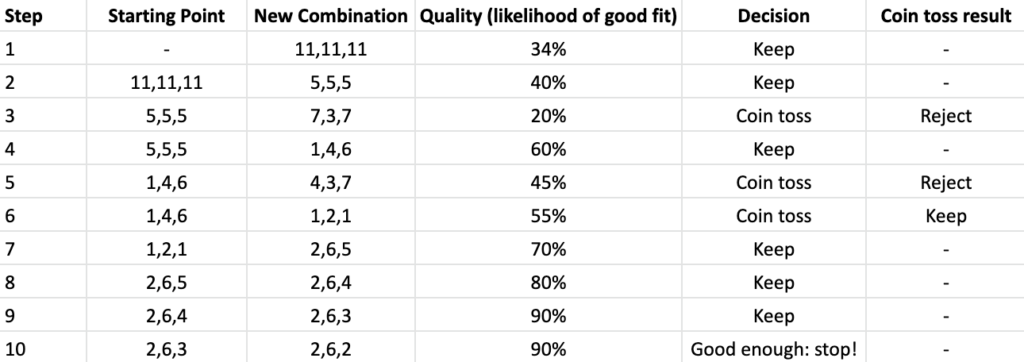
The results of this as applied to galaxy cluster spectra are still available as part of an open-source package, as well as scientific research papers.
Landing it all Back on Earth
People frequently grimace when I tell them that I switched from astrophysics to title and escrow, as if I’d taken Paradise Lost and replaced the final lines with the tax code. (Never mind that the science-to-title switch now seems quite the fashionable thing to do). To me, it flows beautifully: distant objects in the cosmos follow the same rules as those on Earth. That’s what makes it possible to use laboratory physics to understand the origins of the entire universe.
Nothing in my journey makes me appreciate that point more than the application of the MCMC method to title insurance. When it comes to tuning knobs to find the sweet spot, it really doesn’t matter whether it’s galaxy cluster dark matter or real estate risk appetite.
That’s why we adapted my previous research to service our instant underwriting systems at Doma. It did take adding a few tweaks to the algorithm to make it all cohere, but the final combination landed our company its second machine learning patent unique to the title and escrow field (our first patent was on predictive underwriting for title). And it wouldn’t have been possible without my stellar team at the time, Allen Ko and Brian Holligan.
Today, when customers use Doma to refinance their homes, a small part of the speed and efficiency they see flowed from a mathematician in St. Petersburg, through the mind of a magician, up through the stratosphere and back down to Earth, in a demonstration that scientists build on each other’s work with the hope of improving our collective wisdom, or our lives, or hopefully, both.

