

Social Media Marketing and Financial Decision Science are Two Sides of the Same Coin
The modern internet is powered by the distillation of advertising into science. Legions of Americans broadcast their daily lives on social networks such as Instagram and Twitter. They are tolerant (if mildly peeved) that these social networks take advantage of their posts and other monitored activity to optimize advertising efficiency and revenue. And for better or for worse, people do, even if begrudgingly, allow advertising to palpably define their thinking and spending habits. The precise measurement of the effect of advertising on thinking, spending, and speech by the likes of Facebook and Google was in some way the crowning achievement of technology in the 2010s.
When it comes to personal financial information, however, higher standard is necessary. Bank account information, credit reports, credit card bills, and investment accounts aren’t items that the public regularly shares in their interactions with friends. And as such, there is a stronger expectation that companies entrusted with this data share it sparingly and only provide services specifically requested by the consumer.
Yet this data must be shared for many financial activities to take place. Take the apparently straightforward process of changing car insurance providers. When you log in to a car insurance provider’s website, your social security number and birthdate are used behind the scenes to download your full credit report. The credit report contains your most sensitive financial behavior information. This includes not only the overall credit scores, but also the patterns of delinquency, the appetite for credit, and a multitude of other private data points regarding your spending behavior.
A car insurance company uses this information not to decide your ability to pay the insurance premium, but to decide your risk as a driver overall. It turns out that personal financial information, including your credit score, encodes much more than your creditworthiness. It encodes your overall propensity for what I call “risky human behavior,” which in this case is unsafe driving.
It’s a bit disconcerting to think that a single financial data set represents your overall riskiness for not just paying back loans, but for driving behavior, non-payment of taxes, and even the tendency to be sued in court. As unsettling as this is, it is true; the statistical and data science discipline known as decision science takes advantage of this propensity across the entire spectrum of financial services to render decisions that affect your life.
Decision Science with Personal Financial Information Has Risks
Every time someone uses your credit report to render a financial decision, a transfer of data (from one of the credit bureaus or credit-bureau-like entities such as LexisNexis) to the provider occurs. This transfer of data is usually very secure, but the storage and disposition of that data following the transaction is a different matter.
While there are many rules for encryption, retention, and deletion of data, the basic fact is that as you interact with financial services providers, and relay your private financial information to them, you are at the mercy of their ability (and their partners’ ability) to securely store and protect your personal data.
So long as financial services providers have a reasonable cause to hold on to your data (rather than delete it)–such as validation of your car insurance eligibility–they will store it. If they have a permissible purpose, they can continue to monitor your financial credit reports and use them for various modeling and risk estimation purposes. And as the storage of this sensitive data increasingly happens on the cloud, the types of vulnerabilities that lead to security breaches also evolve. Not to mention, many states are passing legislation on the use and retention of personal data which can complicate this even more.
Some of the most well-publicized data leaks over the past 10 years, including Target (2013), Equifax (2017), First American Title (2019), Capital One (2019), all suffered exposure of the personal financial information of borrowers–information used to render insurance and credit decisions.
How Property-Level Decisioning Changes the Game
One way to bolster the security of personal financial information is to simply remove it where it is unnecessary. When it comes to decisioning on real estate risk, it turns out that a wealth of publicly available data exists within county offices and other non-personally-identifying data aggregators, such as Zillow, ATOMdata, Kukun, and HouseCanary. These data sources are free of the most sensitive, personally identifying information and therefore, will typically not run afoul of regulations. Given that they lack confidential information such as credit scores, can such non-personal data be used for financial services decisioning?
The resounding answer, and a recent discovery by Doma and other companies like us, is that for certain use cases, publicly available information about a property holds everything one would need to make robust insurance decisions. The entirety of the history of a home, including all the mortgages, debts, and liens ever recorded, are fully public information that anyone can find out by public records search.
The available public information isn’t limited to just county clerk’s offices. Aerial Photography, which is also considered public information, has found uses within several realms of insurance as a decisioning tool that is fully free of credit-report-like information.
As a result, we can experience an insurance decisioning process that is truly different in its respect for data privacy. In the below image, we compare the traditional insurance decisioning process, which contains a mix of personal and private data, with the property-level decisioning process. For example, a car insurance company might pull a credit report (private information) as well as accident records (public information) and combine them into a single decision.
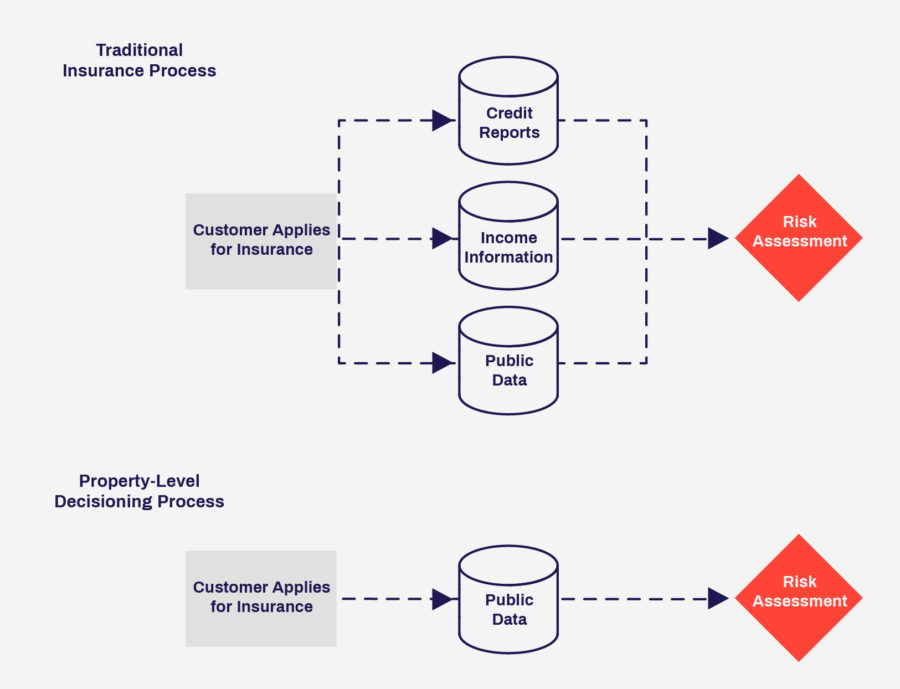
The Doma refinance decisioning engine functions only on public data, making it the only instant title insurance decisioning engine to function in this way as explained in one of our US patents. By minimizing the amount of personally identifying information that flows across multiple vendors and transaction processing companies, customers’ personal data suffers a lower risk of exposure to cybersecurity incidents.
To be sure, once the refinance title insurance process is completed and a decision rendered, we, like every other settlement services company, do need to collect personal information (such as bank account numbers, etc) in order to be able to fulfill the transaction. For example, without this information, we wouldn’t know where to transfer funds. However, as far as the behavioral data contained in credit reports, the Doma refinance decisioning engine is unique in its avoidance of sensitive personal data compared to other instant risk decisioning engines.
Summary: Property-Level Data will fuel the Next Frontier of Decisioning
It has become increasingly clear that certain instant financial services decisions, such as instant refinance title insurance, do not require the use of credit reports and other sensitive personal information. Public data is all that is required–which is on one level a comforting realization, and on another level, leads to new open questions. If information about our financial health is encoded in the properties in which we live, what does this say about the distinction we drew above regarding social data sharing and more private, financial data sharing? Are we witnessing the slow merging of the two? Whatever the answer, it is clear that financial decisioning and human data sharing behavior are locked in a tightly coupled loop. Outside the United States, lenders are explicitly allowed to use social media behavior as part of lending decisions. Thus, the future evolution of the interaction and sharing of public and private data is both tough to predict and a crucial piece of answering the question of how technology is transforming the fabric of society.

